Motivation to use inference endpoints:
Deploying complex AI models, like diffusion models, in a cloud environment poses several technical challenges. These range from the necessity for high-cost, dedicated GPUs, to navigating the cold-start issue associated with auto-scaling, and the intricate demands of ML-ops. Additionally, for those new to the nuances of diffusion models and GPU technology, the learning curve is notably sharp. Fortunately, modern platforms offer these models as managed services, reminiscent of AWS Lambda, streamlining the deployment process. Hugging Face, for example, provides straightforward access to these models, mitigating the traditional barriers to entry.
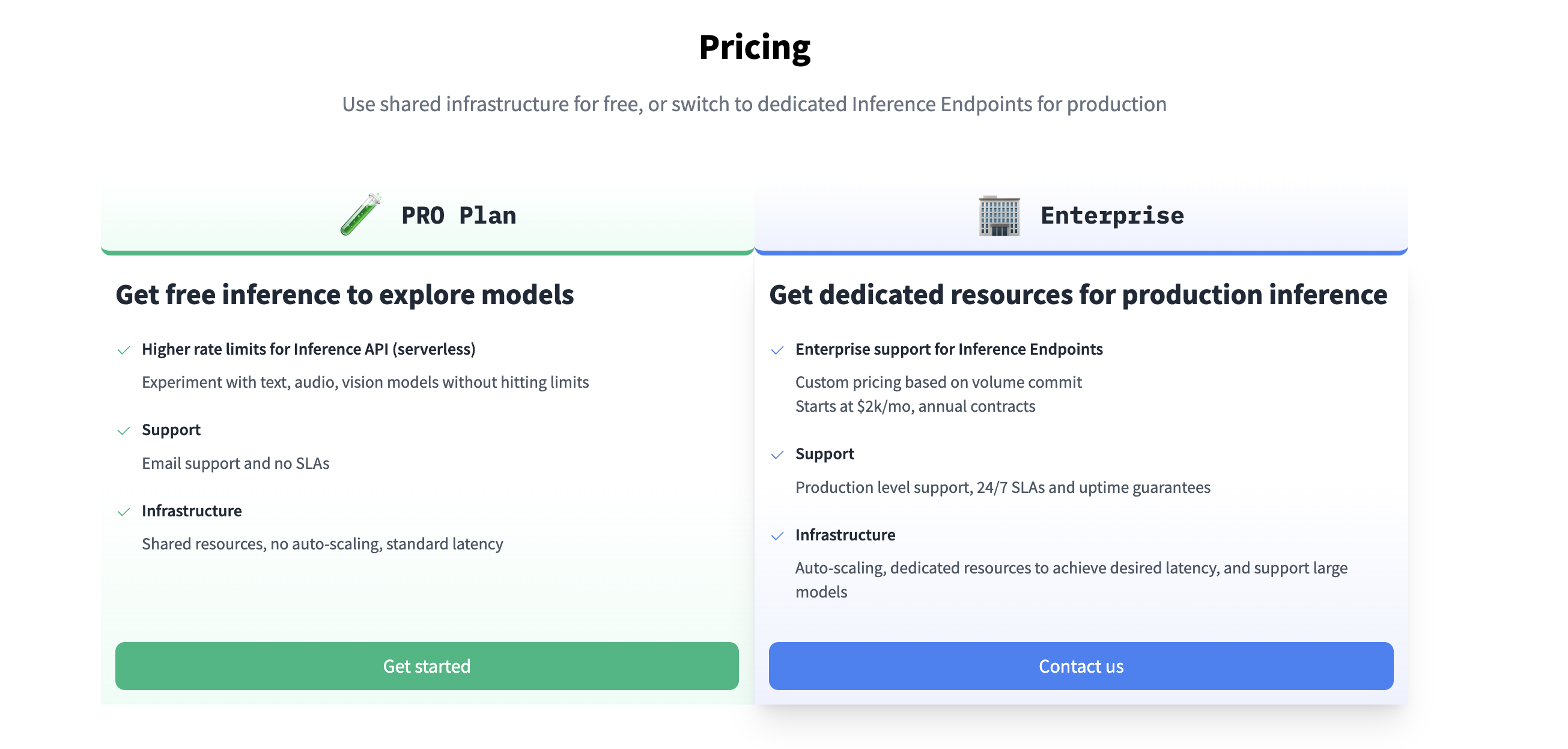
Hugging Face offers two main service tiers for using inference endpoints: the PRO Plan, with higher rate limits and email support but shared resources, and the Enterprise Plan, featuring auto-scaling, dedicated resources, and SLA guarantees, but at a higher cost. I decided to try out the PRO Plan to run a diffusion model.
Getting Started:
First off, visit Hugging Face and navigate to the model you’re keen on. For me, it was Stable Diffusion XL Base 1.0.
Look for the deploy button on the top right, which opens up a code template once clicked on Inference API (serverless) option.
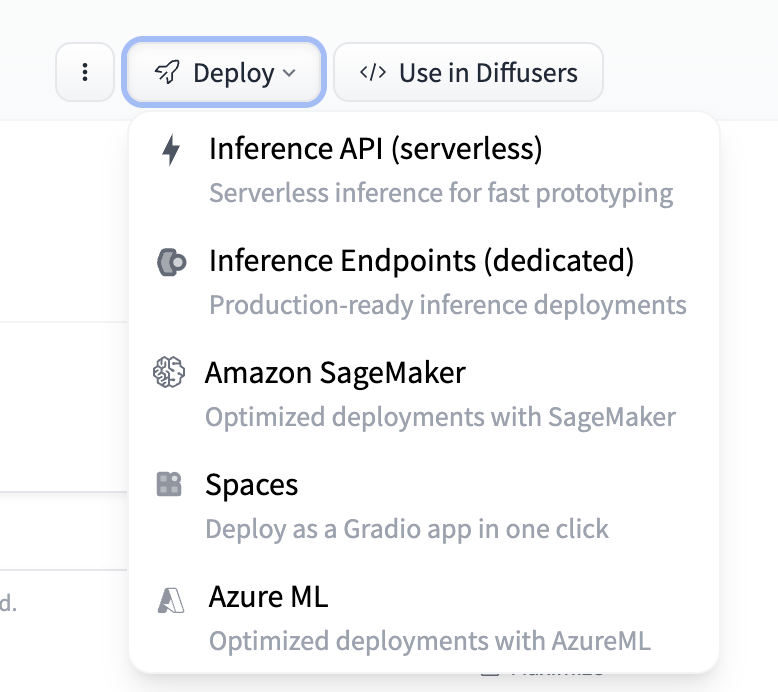
Simply insert your Hugging Face token to run the code.
import requests
API_URL = "https://api-inference.huggingface.co/models/stabilityai/stable-diffusion-xl-base-1.0"
headers = {"Authorization": "Bearer xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.content
image_bytes = query({
"inputs": "Terminator in post apocalyptic world",
})
# You can access the image with PIL.Image for example
import io
from PIL import Image
image = Image.open(io.BytesIO(image_bytes))
image
Alternative to Inference Endpoints:
If you want to run these models on your cloud infrastructure (instead of Inference endpoints), you can do that using either AWS SageMaker or Azure ML Studio. However not all models are available on Azure ML Studio. For example, I didn’t find stabilityai/stable-diffusion-xl-base-1.0 available on Azure model registry. Upon deploying your model on Azure ML Studio, you’re provided with a similar inference endpoint, this time powered by Azure’s cloud infrastructure. I plan to delve deeper into the process of deploying models on Azure ML Studio in a future blog post. While Azure presents a compelling option, it’s worth noting that I haven’t extensively explored the availability of comparable models on AWS SageMaker.
In summary, leveraging Hugging Face’s inference endpoints is a straightforward path to integrating cutting-edge AI into your projects, without the operational overhead.
If you want to check out the code template, you can find it on my github.
